![]()
Exploring noun lexical diversity and noun phrase complexity in Spanish email writing at B1 and C1 levels
![]()
Exploring noun lexical diversity and noun phrase complexity in Spanish email writing at B1 and C1 levels
Natalia Judith Laso Martína – María Belén Díez-Bedmarb
University of Barcelonaa / Spain
University of Jaénb / Spain
Abstract – Research on noun phrase use in EFL writing has mainly focused on linguistic complexity and accuracy, lexical richness, and phraseological competence. However, the relationship between noun lexical diversity of nouns and the syntactic complexity of the noun phrases in which these nouns appear remains underexplored. To address this gap, this paper examines the lexical diversity of head nouns in noun phrases within a sample of emails written by L1 Spanish EFL learners at B1 and C1 proficiency levels, taken from the FineDesc Learner Corpus. The analysis considers both the lexical diversity of nouns and the syntactic complexity of the noun phrases they head. The findings reveal: a) a narrower range of nouns at the B1 level compared to the C1 level; b) a low percentage of nouns from both levels, based on the English Vocabulary Profile; and c) differences in NP complexity between the two proficiency levels (B1 and C1), depending on whether the head nouns are concrete or abstract. The paper underscores the importance of combining different complexity measures ––namely, lexical diversity and NP complexity analyses–– to gain a more comprehensive understanding of learners’ use of noun phrases.
Keywords – lexical diversity; NP complexity; learner email writing; CEFR B1; CEFR C1
1. Introduction1
Much of the past and current literature on the noun phrase (NP) in learner language writing focuses on linguistic complexity and accuracy (Ortega 2003; Biber et al. 2011; Lu 2011; Bulté and Housen 2012, 2014; Ai and Lu 2013; Crossley and McNamara 2014; Parkinson and Musgrave 2014; Liu and Li 2016; Xu 2019; Díez-Bedmar and Pérez-Paredes 2020; Kim 2021), as well as lexical richness and phraseological competence (Howarth 1998; Biber and Conrad 1999; Nation 2001; Hyland 2008; Šišková 2012; Peters 2016; Vedder and Benigno 2016; Paquot 2019; Du et al. 2022). Additionally, the linguistic characteristics of EFL writing have been widely discussed in relation to learners’ L1, topic and genre effects, task complexity, and learners’ L2 level of proficiency (Ellis and Yuan 2004; Ong and Zhang 2010; Díez-Bedmar 2015; Mazgutova and Kormos 2015; Liu and Li 2016; Yoon 2017; Ionin and Díez-Bedmar 2021, among others). However, few studies have approached the analysis of learner language by combining syntactic and lexical complexity measures (see Section 2.3), which prevents a more comprehensive understanding of NP learner production. The present study contributes to the literature by considering two complexity measures, noun lexical diversity and NP syntactic complexity, to study NP production in email L1 Spanish learner writing at different CEFR levels. The levels selected are B1 and C1 and the text type selected is email writing.
The selection of B1 and C1 proficiency levels is driven by our objective to explore the differences between the first level of the independent user (B1_Threshold) and the first level of the proficient user (C1_Effective Operational Proficiency) as defined by the Common European Framework of Reference for Languages (CEFR; Council of Europe 2001). By comparing these two levels, we aim to gain insights into the lexical and syntactic development from an intermediate to an advanced stage of language proficiency.
The choice of email writing is justified by the fact that lexical and syntactic complexity has primarily been analysed in academic language, namely essays, (Šišková 2012; Treffers-Daller et al. 2018; Clavel-Arroitia and Pennock-Speck 2021; Lahuerta 2024, among others) rather than in transactional language. Transactional texts, such as email writing, are not only a prevalent text type in EFL writing but also hold significant importance in high-stakes language accreditation exams. Therefore, this focus allows us to contribute novel insights into an underexplored text type that is highly relevant for EFL learners.
In this study, the classification of nouns into different semantic categories (e.g., concrete vs. abstract nouns, hyponyms within specific semantic fields) is essential for understanding the relationship between noun choice and syntactic complexity. Nouns are central to the structure of NPs, and their semantic properties can influence NP complexity. Moreover, the use of hyponyms provides insight into lexical diversity in learner writing. By analysing noun types and their semantic classifications, we can understand better how learners’ lexical choices at different proficiency levels impact the complexity of the NPs they produce. This classification is directly tied to our research questions, as it allows us to explore whether more abstract or concrete nouns (or nouns from specific semantic fields) are associated with particular patterns of NP complexity at different CEFR levels.
To reach a better understanding of NP learner production by considering two complexity measures, noun lexical diversity and NP complexity types, in email writing at two CEFR levels, our study addresses the following two research questions:
RQ1: How does the type of noun hyponyms used in Spanish EFL email writing production correlate with the English Vocabulary Profile (EVP), according to CEFR proficiency levels?
RQ2: Does the semantic field of the head noun employed affect the NP complexity types produced in email writing by L1 Spanish learners of English at B1 and C1 levels?
In the next section we will examine existing research on NP complexity and lexical diversity, focusing on how these factors relate to CEFR levels and how they support the present study’s research questions.
2. Literature review
2.1. Lexical diversity of nouns in learner writing
Research has shown that lexical diversity ––understood as the range and variety of words used in a text, and, more specifically, lexical variation, focused on lexical words–– are key indicators of language proficiency, particularly in EFL contexts (Engber 1995; Crossley et al. 2011; Kuiken et al. 2010; Housen et al. 2011; Lu 2012; Vidal and Jarvis 2020; Allaw 2021). The exploration of lexical richness within the framework of proficiency levels defined by the CEFR has gained significant attention in recent learner corpus-based studies. Šišková (2012), for instance, conducted a study on lexical richness in narratives written by Czech EFL learners. Focusing on various measures of lexical diversity, the research revealed strong correlations between various indicators of lexical richness and underscored the importance of vocabulary knowledge in language acquisition. In a related study, Gregori-Signes and Clavel-Arroitia (2015) explored both lexical density and lexical diversity across different writing tasks produced by university EFL learners at B1 and C2 levels. Their examination of writing tasks revealed a progression in lexical diversity across proficiency levels. This progression of lexical diversity B1-C2 highlights the importance of learner corpus research cross-sectional studies in assessing proficiency levels by examining lexical diversity in learner corpora. In a similar vein, other studies, such as Treffers-Daller et al.’s (2018), contribute to ongoing discussions on how lexical diversity measures can assist in differentiating essays by proficiency level. Their study revealed that basic measures of lexical diversity, such as the number of different words and type-token ratio (TTR), exhibited strong predictive power in discriminating between proficiency levels when controlling for text length. This finding underscores the usefulness of fundamental lexical indices in assessing language proficiency accurately.
Expanding on the investigation of lexical complexity, Su et al. (2023) conducted a nuanced analysis of exemplar EFL texts across different grade levels in China. They identified specific lexical diversity and sophistication features as effective markers of lexical complexity and explored their implications for assessing language proficiency and guiding text adaptation practices. Furthermore, Clavel-Arroitia and Pennock-Speck (2021) compared lexical density, diversity, and sophistication in written and spoken interactions of university students during English as a lingua franca telecollaborative exchange. While Spanish learners exhibited higher lexical diversity and sophistication in their written production, the differences in the oral production were subtler, suggesting context-dependent variations in lexical usage.
In addition to corpus-based investigations, theoretical frameworks have been developed to model lexical proficiency accurately. Crossley et al. (2011) undertook a thorough examination of lexical diversity in written texts, highlighting its close correlation with students' language proficiency levels. They proposed a model of lexical proficiency based on computational indices, including those related to noun usage. Their findings indicate that the number of different words, word hypernymy values, and content word frequency in a text gradually increases across different proficiency levels, reflecting thus a gradual increase in lexical diversity. The observation by Crossley et al. (2011) aligns with Qin and Uccelli’s (2020) study, where they employed multi-level linear models to analyse lexical diversity as a dependent variable to capture differences associated with English proficiency. They found that lexical diversity increases throughout the language learning process, and it is often associated with more diverse vocabulary in academic writing.
Despite the wealth of research on lexical diversity and its implications for language proficiency in EFL writing, there remains a gap in understanding the lexical diversity of nouns within the CEFR framework in Spanish EFL written production. Therefore, an in-depth analysis of the lexical diversity of nouns in a learner corpus of Spanish EFL learners’ email writing at B1 and C1 levels can enhance our understanding of the development of linguistic proficiency in EFL writing.
2.2. NP complexity in learner writing
Skehan’s (1989) three-part model of L2 proficiency, which considers complexity, accuracy and fluency (CAF), has shaped the research conducted to analyse (learner) language production. Specially since Wolfe-Quintero et al.’s (1998) and Ortega’s (2003) research syntheses, a plethora of publications have employed CAF measures to analyse texts produced by speakers in the target variety (e.g., English as an L1) and by speakers from other varieties, such as the learner varieties (e.g., Spanish learners of English).
The most frequently analysed type of complexity is syntactic complexity, which is defined as “the range and the sophistication of grammatical resources exhibited in language production” (Ortega 2003: 82), “the progressively more elaborate language that may be used, as well as a greater variety of syntactic patterning” (Foster and Skehan 1996: 303), or “a wide variety of both basic and sophisticated structures” (Wolfe-Quintero et al. 1998: 69). Therefore, the variety of syntactic forms produced, their sophistication, and degree of elaboration have been considered in the analyses of syntactic complexity.
The study of syntactic complexity at NP phrase level has been advocated for so that language complexification at different levels can be captured, thus allowing for the description of the multidimensional nature of the syntactic complexity construct (Norris and Ortega 2009; Biber et al. 2011; Lu 2011; Kyle and Crossley 2018; Casal and Lee 2019; Lan et al. 2022; Zhang and Lu 2022). The analyses have been conducted by using a variety of measures which, in different ways, have taken into consideration the constituents in the NP. Some studies have drawn from Biber et al.’s 2011 syntactic developmental index (e.g., Parkinson and Musgrave 2014; Staples et al. 2016; Ansarifar et al. 2018; Casal and Lee 2019; Lan et al. 2019). Other publications have operationalised NP complexity by considering the number of constituents in the NP with length measures (see Ravid and Berman 2010; Kuiken and Vedder 2019; Lu and Wu 2022, among others). Other studies have considered the so-called ‘complex nominal’, even though differences in the operationalisation of such measure are found. For instance, the complex nominal is defined by Lu (2010: 483) as a noun which is modified by means of an attributive adjective, possessive noun, post-preposition, relative clause, participle or appositive, a noun clause, as well as gerund and infinitival subjects. However, Vyatkina (2013) considers within complex nominal structures attributive adjective phrases, prepositional phrases extending nominal phrases, nominal clauses, and relative clauses. Caution is therefore to be taken when comparing the results obtained in the different studies on the topic, as NP complexity is operationalised in different ways.2
Taking as a starting point the syntactic complexity measures in Wolfe-Quintero et al.’s (1998) and Ortega’s (2003), software such as the L2 Syntactic Complexity Analyzer (L2SCA; Lu 2010) and the Tool for the Automated Analysis of Syntactic Sophistication and Complexity (TAASC; Kyle 2016) have been developed to automatically analyse a number of syntactic complexity measures at sentential, clausal, and phrasal levels. Consequently, some publications have combined both, the automatic analysis, and the manual analysis to aim for a comprehensive analysis of NP complexity. For instance, Díez-Bedmar and Pérez-Paredes (2020) employed the nominal measures in TAASC and conducted a manual parsing of the syntactic complexity of all NP types, which revealed 29 different NP types divided into simple NPs (i.e., determiner NPs), premodified NPs, postmodified NPs, and pre- and postmodified NPs. The results showed that a combination of both analyses provide the more exhaustive results in the analysis of NP complexity in learner language, as NP is operationalised in different ways and a more fine-grained analysis may be obtained.
Despite the wealth of studies on NP complexity, there is little information on NP complexity considering different CEFR levels. To the best of our knowledge, most of the studies available do not focus on the NP exclusively, but measures related to the NP are found together with other syntactic complexity measures. This is the case of Khushik and Huhta (2020), who offered information regarding complex nominals per clause and complex nominal per T-unit,3 and modifiers per noun phrase and noun phrase density, and Lahuerta-Martínez (2018, 2023), who included the measures noun phrases per clause and mean length of noun phrase, respectively. Only the study by Díez-Bedmar and Pérez-Paredes (2020) and Sarte and Gnevsheva (2022) paid exclusive attention to NP complexity.
Since NP complexity is typical of academic writing (Biber et al. 2011, 2021), text types in that writing context have been the most frequently analysed ones (e.g., argumentative texts). As a result, there is a gap in the literature regarding the study of NP complexity in other text types which are not considered academic prose, such as email writing. These studies are, in fact, necessary to analyse the effect that text type, genre, and even topic ––which have been shown to affect syntactic complexity–– may have on NP complexity and consequently reach a more exhaustive understanding of NP complexification in learner language (Biber and Gray 2011; Lu 2011; Polio and Park 2016; Staples et al. 2016; Staples and Reppen 2016; Bernardini and Gradfeldt 2019; Lan et al. 2019; Sarte and Gnevsheva 2022).
2.3. Analysing lexical diversity and syntactic complexity
The existing body of research exploring the interaction of different CAF measures is relatively limited, with many studies focusing on isolated aspects such as lexical diversity or syntactic complexity. Studies that consider different complexity types are also scarce, but some isolated hints here and there. In a 12-month longitudinal case study with an untutored L1 Turkish learner of English, Polat and Kim (2014) analysed accuracy ––by means of a global measure and one which focused on the present simple tense–– as well as syntactic complexity ––mean length of speech unit (AS-unit)4; clauses per AS-unit and mean length of clauses–– and lexical diversity ––using the measure of lexical diversity D–– in the participant’s speech in oral interviews. The results indicated that the only clear improvement was seen in the participant’s vocabulary, with increased lexical diversity. Another longitudinal study exploring lexical and syntactic complexity was conducted by Kisselev et al. (2022) who analysed a learner corpus of Russian with argumentative and narrative essays written by students at different proficiency levels. Lexical complexity was operationalised by means of the mean word length and the lexical frequency profile (at A1 and B2 levels). Syntactic complexity was analysed by means of measure of textual lexical diversity (MTLD) by lemma, MTLD by wordform, mean sentence length, clauses per sentence, coordinate clause ration, subordinate clause ratio, syntactic depth ratio, relative clause ratio, infinitive clause ratio, participle clause ratio, and gerund clause ratio. The results show that nine indices ––namely, mean word length, type-token ratio, percentage of high-frequency words, mean sentence length, clauses per sentence, syntactic depth, proportion of subordinate clauses, and proportion of relative clauses–– showed differences in the course of the eight-week instruction programme and, for clauses per sentence, correlated with the results of the initial placement test and the final proficiency test.
Gaillat et al. (2022: 132) employed ‘microsystems’ ––i.e., “families of competing constructions in a single paradigm”–– to classify learner texts from A1 to C2 levels. Their results showed that, although the consideration of lexical (lexical variation and lexical sophistication), syntactic (syntactic complexity), and pragmatic features (cohesion) in learner writing, as well as their accuracy (considering average misspelling every 50 words) as retrieved by the software LCA (Lu 2012), TAALES (Kyle and Crossley 2015), L2SCA (Lu 2010), TAACO (Crossley et al. 2016) are important to predict CEFR levels and show that lexical and syntactic features play a determinative role in the prediction.
Lahmann et al. (2019) analysed different measures of linguistic complexity in the spontaneous oral production by German-English bilinguals living in an English-speaking country to reveal clusters of grammatical and lexical complexity measures. To do so, measures at syntactic level (sentence and clause, sub-clause, and phrase), morphological level and at lexical level (diversity and sophistication) were considered. The results reveal that the cluster for grammatical complexity measures include length measures and subordination ratios regarding grammatical complexity, without forgetting measures for sentence types and morphology. As for lexical complexity, lexical diversity, frequent lexical items, and the use of abstract words were important in the cluster for lexical complexity.
Finally, Lambert and Nakamura (2019) studied clausal (the proportion of simple utterances, compound utterances, complex utterances based on nominal subordination, adverbial subordination, and relative subordination), phrasal complexity (words per NP, modifier tokens per NP, modifier types per NP, subordinate nouns per NP) as well as the abstractness of the head nouns in the oral production by 36 L1 Japanese learners of English at different proficiency levels, also considering the production by 18 L1 English peers. Among the results, the role played by the students’ access to task-relevant lexis as a moderating variable is highlighted. Regarding the relation between phrasal complexity and lexis, the more proficient students were found to produce specific words more frequently than lower-level students, who compensated their lack of specific vocabulary with more complex NPs. In NPs whose head were the nouns ‘part’, ‘thing’, and ‘place’, the most frequent postmodifier was the relative clause. Lambert and Nakamura’s identification of task-relevant lexis as a moderating variable aligns with some of our findings, particularly regarding how more proficient learners tend to use specific vocabulary and some NP complexification types. By incorporating these perspectives, our study aims to contribute to the ongoing discussion on language acquisition, potentially offering new angles for both theoretical exploration and practical applications in language teaching and assessment.
In conclusion, while research on the interaction of different complexity measures in learner language remains relatively scarce, the studies reported here underscore the multifaceted nature of linguistic development. Our study aims to extend these findings by examining the interplay between lexical diversity and syntactic complexity across different proficiency levels, thus providing a broader perspective. By combining diverse complexity measures, our research contributes to a more comprehensive understanding of NP learner language production.
3. Methodology
3.1. The learner corpus
The learner corpus used in this study is a subsection of the FineDesc Learner Corpus, which is being compiled within the FineDesc Research Project, funded by the Spanish Ministry of Science Innovation and Universities, with the pass-only texts by L1 Spanish candidates who have taken the high-stakes CertAcles Exam Suite at B1, B2, or C1 level in Spanish University Language Centres.5 In the exam, candidates are asked to write two different texts which are evaluated by two professional independent raters. Only those texts which meet the requirements of the level (B1, B2, or C1, depending on the exam taken), as determined by two experienced CEFR raters who evaluate high-stakes examinations in University Language Centres in Spain, are included in the FineDesc Learner Corpus after they are fully anonymised and transcribed into electronic format (txt files).
The subsection considered for this study consists of 90 texts at two CEFR levels (amounting to 18,134 words), as shown in Table 1.
|
Level |
Number of texts |
Number of words |
Mean and Standard Deviation |
|
B1 |
44 |
6,795 |
M= 154.43 / SD= 31.36 |
|
C1 |
46 |
11339 |
M= 246.50 / SD= 41.04 |
|
Total |
90 |
18,134 |
|
Table 1: An overview of the learner corpus employed
Students at both levels were asked to react to the same prompt (reply to a friend’s email), but using a different number of words, depending on the level (see Figure 1). As can be seen in the data in Table 1, students aimed at the highest number of words required per level. Candidates at B1 wrote a mean of 154.43 words (the maximum number of words required was 150) and those at C1 level produced a mean of 246.50 words (the maximum number of words required was 250). The difference in the means of words per text type proved to be statistically significant (p= .000; z= -7.269; U= 111.500). Normalisation of the data per 1,000 words was, therefore, calculated to compare the results across the two subcorpora.

Figure 1: Prompt provided to students for the writing task
3.2. Noun lexical diversity
This study examines a total of 680 noun lexemes extracted from a corpus of B1 (44 texts; 6,795 tokens) and C1 (46 texts; 11,339 tokens) emails taken from the FineDesc Learner corpus. The sample consisted of 90 emails, which were POS tagged using Freeling (Padró et al. 2010; Padró and Stanilovsky 2012). All noun lexemes were first disambiguated by means of the UKB option (Agirre et al. 2018) in Freeling, a word sense disambiguation tool, which helps identify the correct sense of a word in a given context when the word has multiple meanings, and they were later annotated using WordNet (Fellbaum 1998).
A total of three (direct and inherited) hypernyms were retrieved and manually annotated, creating a hierarchical list from the most specific (direct hypernyms) to up to three levels of inherited hypernyms. A direct hypernym is the immediate parent category or class of a given word (or synset) in the WordNet hierarchy, while inherited hypernyms include all ancestor categories or classes of a word, not just the immediate parent. The hierarchical list included up to three inherited hypernyms due to the observation that the semantic relationships provided by the first few levels of inherited hypernyms are generally sufficient to capture the essential context or distinctions relevant to the task.
In some instances, the output from Freeling failed to generate accurate part-of-speech (PoS) annotations. For instance, some base forms were misanalysed as nouns instead of as bare infinitives, as illustrated in Figures 2 and 3. Consequently, a manual review of the automatic annotation was necessary. Additionally, WordNet annotations, based on hypernyms and hyponyms, were also fine-tuned. This adjustment was essential since certain lemmas with polysemous senses ––such as the distinction between ‘experience’ as an ability (background training, qualifications, etc.) and ‘experience’ as an event (something that happened on a given occasion)–– had not been accurately disambiguated according to the specific context.

Figure 2: Adjustment of Freeling’s PoS annotation (C1 corpus, example 1)
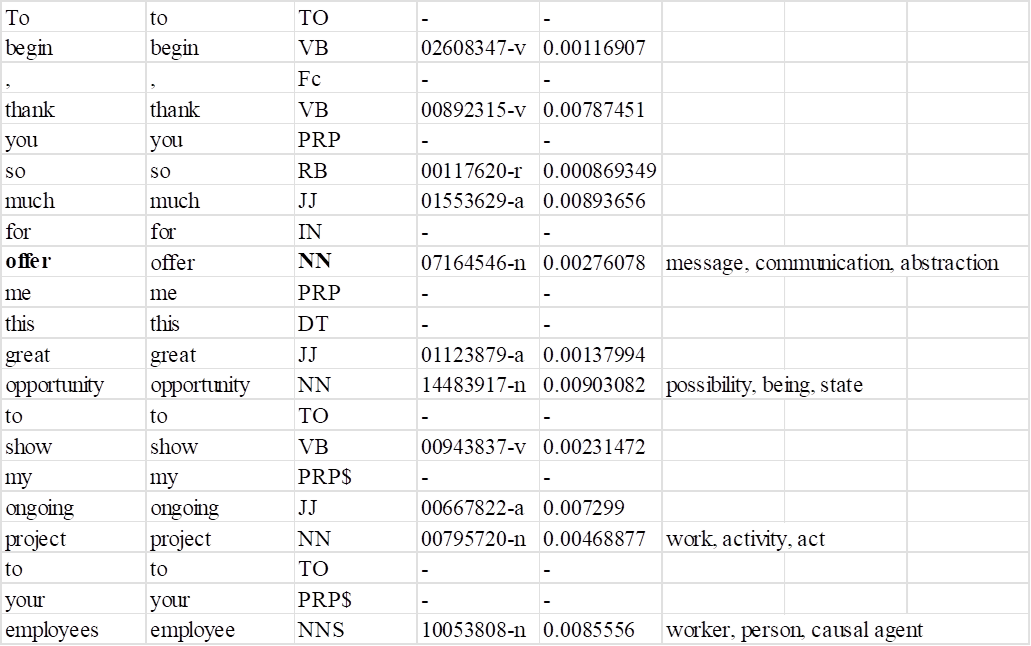
Figure 3: Adjustment of Freeling’s PoS annotation (C1 corpus, example 2)
Subsequently, the list of nouns from the B1 corpus (a total of 304 noun lexemes) and the list from the C1 corpus (a total of 664 noun lexemes) were classified as hyponyms of the selected hypernym terms. Two databases of semantic fields (B1 and B2, respectively) were then established. The B1 database for nouns comprises 45 hypernyms, while the C1 database consists of a total of 65 hypernyms (see Appendices 1 and 2). To this respect, it is worth noting that the predictor of the semantic field of the head noun is introduced to investigate whether the context in which a noun is used influences NP complexity types. By examining the semantic fields, we aim to uncover patterns that may not be evident through a purely syntactic or lexical analysis.
Finally, the English Vocabulary Profile (EVP), a tool which provides detailed information about which words are typically produced by learners at each CEFR level, was consulted to verify if the noun hyponyms employed by B1 and C1 learners were classified into the B1 and C1 levels according to the tool. This study, therefore, uses the EVP to align the types of noun hyponyms used in Spanish EFL email writing with the learners’ proficiency levels, providing a more precise analysis of lexical diversity.
3.3. NP complexity
In this study, NP complexity was operationalised by considering premodified NPs, postmodified NPs, and pre- and postmodified NPs (Biber et al. 2021: 568–642; examples are shown in Table 2––see Section 3.4 below). Since the main aim of the study is to provide an overview of NP complexity considering the effect that the head noun may have on NP complexity in email writing at different levels, no further analysis has been conducted regarding the specific linguistic structure employed by the learner to premodify, postmodify or pre- and postmodify the head of the NP.
3.4. Annotation procedure
To analyse the semantic field of the head noun in the NP and the complexity NP type employed, a two-step procedure was followed once the 2,046 NPs in the learner corpus had been identified. First, each head noun was annotated to specify the semantic field to which it belonged. To do so, the first layer of annotation was manually inserted by employing a tag which indicated one of the 36 semantic fields considered, as in examples 1 and 2:
(1) more (communication) details about your mates (C1_8)
(2) the (ability) methods we use to potentially increase… (C1_5)
Then, the second layer of information was added to account for the NP complexity type in each NP, as can be seen in (3) and (4) below, using the taxonomy in Table 2. As a result, the two layers of information provided both the lexical information and the syntactic complexity information necessary to conduct this study in a total of 981 NPs which showed premodification, postmodification or pre- and postmodification. The remaining 1,065 NPs in the learner corpus were determiner NPs (i.e., NPs without any complexification) and were not considered in the study.
(3) more (communication _post) details about your mates (C1_8)
(4) the (ability_ post) methods we use to potentially increase… (C1_5)
|
NP complexity type |
Tag |
Learner example |
|
Premodification |
(prem) |
(prem) Technological devices (C1_17) |
|
|
|
(prem) A brief and light talk (C1_18) |
|
Postmodification |
(post) |
(post) risk of coronavirus (B1_1296) |
|
|
|
(post) Advice on other relevant aspects (B1_1297) |
|
Pre- and postmodification |
(prem_post) |
(prem_post) New things about my culture (B1_1294) |
|
|
|
(prem_post) Different family plans to do in the city (B1_1267) |
|
|
|
(prem_post) the urban bus, that is quite cheap, (B1_1270) |
|
|
|
(prem_ post) The worst public transport of Spain (B1_1295) |
Table 2: The NP taxonomy employed and examples (head nouns are underlined)
To retrieve all the occurrences of each NP complexity type per semantic field, the software Tags Retrieval (Martínez Mimbrera 2021) was employed. The information was then transferred to SPSS for subsequent statistical analyses. Due to the non-normal distribution of the data (p<.05), Mann-Whitney tests were run to single out the statistically significant differences in the use of the different NP complexity types in B1 and C1 email learner writing when using head nouns which belong to semantic fields typically attested in the B1 or C1 level.
4. Results and discussion
4.1. Noun lexical diversity
The study involved a sample of 884 noun lexemes, with a lower range of lexeme nouns in the B1 corpus (274) compared to the C1 learners’ sample (610). The general results of the most prototypical hypernyms found in the B1 learner corpus are shown in Figure 4:
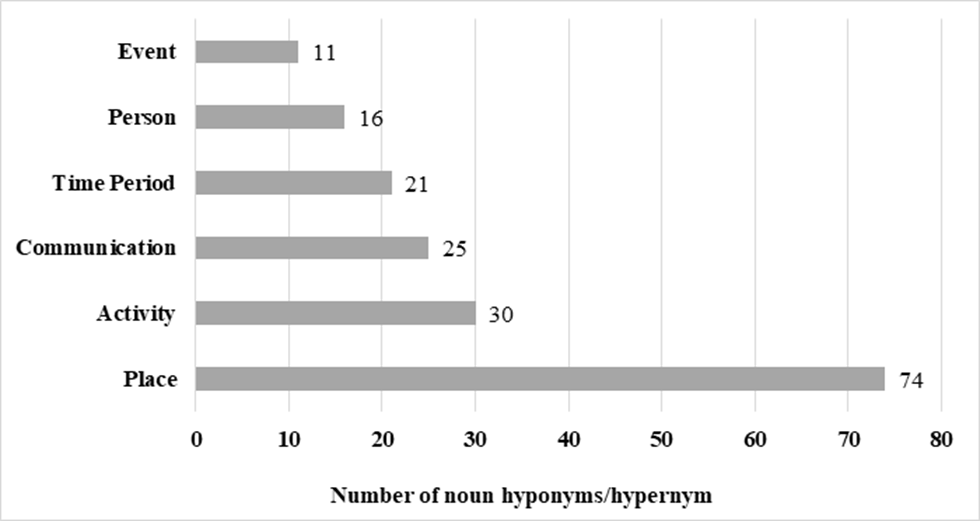
Figure 4: Most salient noun hypernyms in the B1 database
As illustrated in Figure 4 above, there are six noun hypernyms particularly used in the B1 corpus (i.e., place, activity, communication, time period, person, and event) each of them with more than ten hyponyms. These fields are closely related to the thematic situation presented in the writing task assigned to the participants, which asked them to respond to an email from a friend they had met the previous year in Switzerland. and who plans to visit Spain with their family. Additionally, the friend takes the opportunity to invite the candidate to give a talk to a group of employees in their company. The candidate is asked to address the following bullet points which trigger words from the hypernyms between brackets:
(a) Recommend various family plans to undertake in their city (e.g., activity, place, event);
(b) Express gratitude to the colleague for the invitation to speak before their workers (communication, person);
(c) Outline the topics the candidate would like to address in the talk (communication, person);
(d) Suggest a Skype meeting to discuss these matters more thoroughly (communication, time period).
A more detailed analysis of each of the six most salient hypernyms allows for the observation of the range of noun hyponyms comprising each semantic field, as shown in Figure 5 below.
|
Place |
Activity |
Communication |
Time Period |
Person |
Event |
|
School |
Course |
Question |
Summer |
Secretary |
Landmarks |
|
Home |
Sport |
|
Week |
Friend/s |
Situation |
|
University |
Activity |
Information |
Morning |
Adult/s |
Visit |
|
Camp |
Travel |
Advertisement |
Year |
Children |
Matches |
|
Hotel |
Exercise |
Response |
Weekend |
Instructors |
Party/ies |
|
Place/s |
Job |
Contact |
Evening |
Student/s |
Attraction |
|
Canteen |
Exams |
Answer |
Hours |
Players |
Fair |
|
Showers |
Attention |
Conclusion |
Age |
Roommate |
Festivity |
|
Country/ies |
Help |
Offer |
Date |
Experts |
festival |
|
Camp |
Ride |
Letter |
Holiday/s |
Parents |
Event |
|
House, houses |
Plan, plans |
News |
Autumn |
Brother |
Shows |
|
Village/s |
Project |
Music |
Day |
Cousins |
|
|
Office |
Trip, trips |
Advice |
October |
Colleague |
|
|
Area |
Routes |
Reply |
Nights |
Tourist/s |
|
|
City/ies |
Scape room |
Regard/ |
Moment |
Kids |
|
|
Companies |
Trekking |
Ticket/s |
Afternoon |
Waiter |
|
|
Shops |
Mountain-climbing |
Story/ies |
Season |
|
|
|
Restaurant/s |
Dancing |
Goodbye |
Times |
|
|
|
Pubs |
Degree |
Recommendations |
Month |
|
|
|
Cinemas |
Care |
Tips |
|
|
|
|
Mountain |
Tourism |
Card |
|
|
|
|
Monument/s |
Hiking |
Media |
|
|
|
|
Cathedral |
Climbing |
Archive |
|
|
|
|
World |
Cycling |
webpages |
|
|
|
|
Liverpool |
Walking |
|
|
|
|
|
Santiago de Compostela |
Shopping |
|
|
|
|
|
Jaén |
Project |
|
|
|
|
|
Spain |
Hugs |
|
|
|
|
|
Sierra Cazorla |
Kisses |
|
|
|
|
|
Arab Baths |
|
|
|
|
|
|
Town/s |
|
|
|
|
|
Figure 5: Noun hyponyms in the selected hypernyms from the B1 database
The data reveal that the most prototypical semantic fields in the B1 texts correspond to more concrete areas, consistent with the expected vocabulary associated with B1, which tends to be more concrete, practical, and focused on everyday situations. For example, the hypernym activity includes hyponyms such as sport, hiking, cycling, and shopping, which are typical activities one might recommend for a family visit. Similarly, the hypernym communication includes nouns like email, call, and talk, reflecting the communicative actions required by the task.
In terms of vocabulary and topics, learners at the B1 level often engage with everyday situations, personal experiences, hobbies, travel, and simple professional topics (Council of Europe 2001, 2020; North 2021). It is also noteworthy that some of the nouns used correspond to lexical items lifted directly from task instructions (e.g., course, friend, secretary, school, accommodation). This reliance on task-related vocabulary indicates a tendency for B1 learners to use familiar and concrete nouns that are closely tied to the given context.
By contrast, according to the EVP, the list of nouns (hyponyms) used in the B1 learner corpus predominantly corresponds to nouns associated with lower CEFR levels. As illustrated in Figure 6, the comparison between the noun database in the B1 learner corpus of email writing and the EVP shows that only 21.90 per cent of the nouns in the learner corpus are B1 nouns in the EVP, while the majority of the nouns used (62.04%) are categorised in lower levels; for instance, school, summer, things, friend, sport, train, weather, job, food (A1), and office, story, team, moment, nature, luggage, information, exercise (A2) in the CEFR. This indicates that B1 learners frequently use basic nouns that are well within their comfort zone and are likely to encounter in everyday interactions.
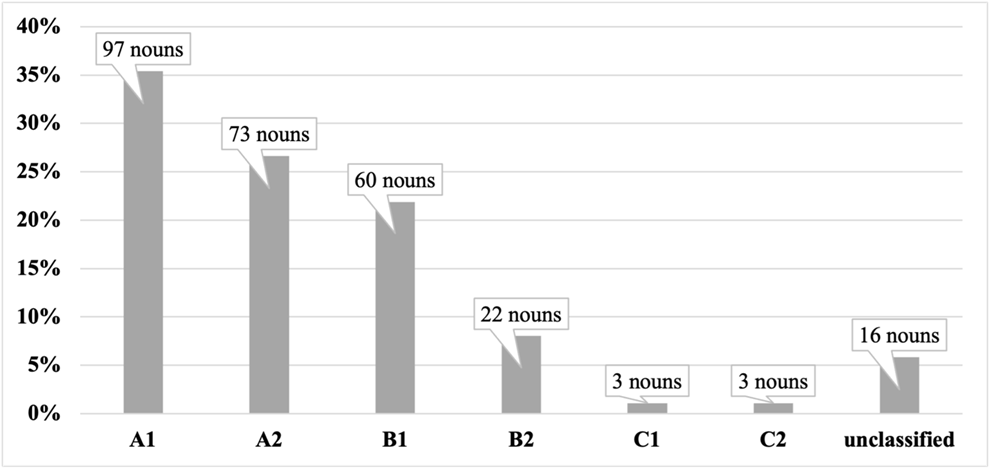
Figure 6: Comparison between the noun database in the B1 corpus and the EVP
In the C1 learner corpus, the general results regarding the most prototypical hypernyms reveal an increase in the range of nouns belonging to different semantic fields. As shown in Figure 7, the noun hyponyms associated with the hypernyms of communication, activity, time period, person, and event are also the most frequently used, although in different proportions. While in B1 we observed that activity was the most frequent, followed by communication, in C1, we see that the use of nouns in the communication field is higher than that of activity.
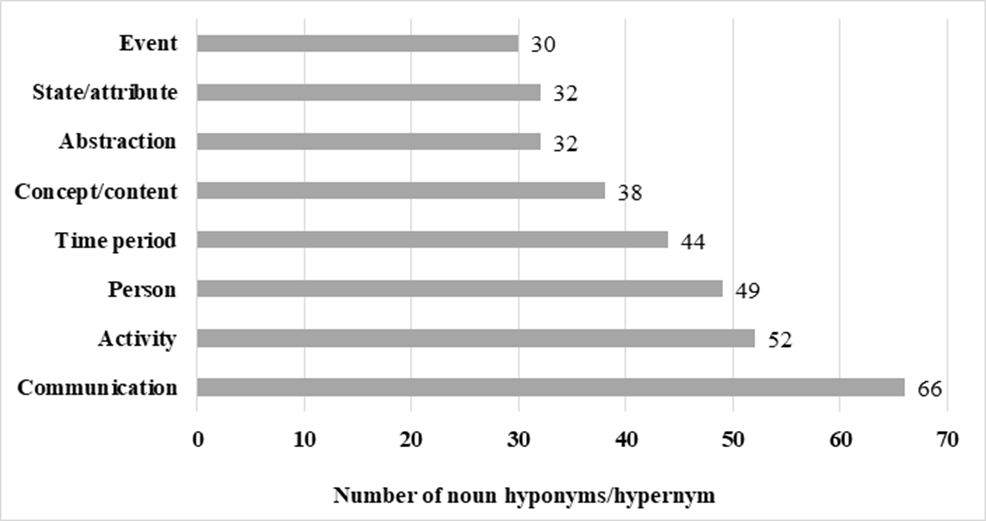
Figure 7: Most salient noun hypernyms in the C1 database
Figure 8 shows the data for the analysis of the actual hyponyms of the most salient hypernyms in the C1 corpus:
|
Communication |
Activity |
Person |
Time Period |
Concept/content |
Abstraction |
State/attribute |
Event |
|
Talk/s |
Work/s |
Employee/s |
Moment |
Content/s |
Knowledge |
Friendship |
Festival |
|
Communication |
Project/s |
Students |
Future |
Topic/s |
Situation/s |
Advantage/s |
Event/s |
|
(Phone) call |
Activity/ies |
Customers |
Lifetime |
Theme |
Level |
Pitch |
Time (occasion) |
|
|
Preparation |
Workers |
Day/s |
Subject/s |
Way/s |
Atmosphere |
Impact |
|
News |
Practice |
Followers |
Hour/s |
View/s |
Time |
Relationship/s |
Change/s |
|
Suggestions |
Investigation/s |
Mate/s |
Break |
Field/s |
Depth |
Position |
Championship |
|
Answer |
Care |
Doctor |
School |
Discipline/s |
Background |
Personality |
Video-conference |
|
Message |
Classes |
Designers |
Summer |
Architecture |
Duration |
Life |
Discovery |
|
Question/s |
Education |
Boy |
Week/s |
Technology/ies |
Spirituality |
Control |
Performance |
|
Speech/s |
Attention |
Members |
Yesterday |
Matter/s |
Relevance |
Mindfulness |
Participation |
|
Consideration |
Research |
Co-workers |
Ages |
Norms |
Motivation |
Quality |
Accidents |
|
Discussion |
Task/s |
Managers |
Year/s |
Science |
Arrangement/s |
Childhood |
Championship |
|
Encouragement |
Teamwork |
Husband |
Month |
Law |
Connection |
Degree |
Convention |
|
Tips |
Service/s |
Children |
Monday/s |
Goal/s |
Ethics |
Benefits |
Implementation |
|
Expression |
Process |
Kids |
Morning/s |
Idea/s |
Relation |
Attitude |
Conference/s |
|
Thanks |
Career |
Toddlers |
Holidays |
Expectation/s |
Need |
Doubt/s |
Meeting/s |
|
Paragraphs |
Exercise/s |
Producers |
Date/s |
Mind |
Dynamics |
Quantity |
Demonstration |
|
Advice |
Job |
Counsellors |
Tomorrow |
Inspiration |
Protocol |
Postures |
Workshop/s |
|
Songs |
Hobby |
Therapists |
Session/s |
Thought/s |
Act |
differences |
Improvement/s |
|
Negotiation/s |
Practice |
Victims |
Afternoon/s |
Rules |
Rights |
Danger |
Appointment/s |
|
Promotion |
Training |
Lawyer |
Times |
Studies |
Pressure |
Aspect/s |
Distribution |
|
Proposal |
Tricks |
Scholar |
Right |
Objectives |
Responsibilities |
Disadvantages |
Spread |
|
Conversation/s |
Instruction/s |
Person |
Weekend/s |
Aim/s |
Functions |
Reality |
Video-conference |
|
Voice/s |
Course/s |
Speaker |
Decades |
Issue/s |
Security |
Perks |
Progress |
|
Arguments |
Treatment |
Spectators |
Today |
Concept |
Resources |
Privilege |
Steps |
|
Information |
Efforts |
Experts |
Fortnight |
Plan/s |
Rates |
Wellbeing |
Convention |
|
Document |
Use |
Workmates |
Leisure |
Strategy/ies |
Proactivity |
Circumstances |
Experience |
|
Summary |
Brainstorming |
Assistants |
Phases |
Policy |
Organisation |
Reputation |
Championship |
|
Statement |
Cooperation |
Employer |
Evening |
Economy |
Obligations |
Account |
End |
|
Offer |
Role/s |
Colleagues |
Minute/s |
Access |
Protocol |
Environment |
|
|
Communications |
Review |
Engineers |
(in) Advance |
Psychology |
|
Self-harm |
|
|
Reply |
Mediation |
Clients |
Friday/s |
Energy |
|
|
|
|
Response |
Errands |
Participants |
Pace |
Budget/s |
|
|
|
Figure 8: Noun hyponyms in the selected hypernyms from the C1 database
As mentioned in Section 3, C1 learners were asked to produce the same writing task as the one provided to B1 learners. Due to the task’s typology and topic, the high frequency of nouns falling into the semantic fields of communication (e.g., consideration, negotiation, statement), person (e.g., customer, followers, co-workers, assistants, engineers), and event (e.g., championship, convention) was also noticeable in the B1 sample. However, as expected, the most notable aspect in C1 texts is the incorporation of hypernyms related to concepts that are more abstract. As shown in Figure 8, this includes categories such as concept/content (38 nouns), abstraction, and state/attribute (32 nouns each).
At the C1 level, learners are expected to handle more nuanced vocabulary, allowing them to engage in discussions on a wide range of topics, including those of an abstract nature. Thus, they are likely to encounter and use words that are more precise, sophisticated, and context-dependent compared to learners at the B1 level. Examples of these words are topic, matter, expectation, mind, goal (concept/content); knowledge, background, relevance, arrangement (abstraction); and advantage, friendship, childhood, or mindfulness (state/attribute).
The comparison with the EVP reflects the same trend noticed in the B1 learner corpus. Only 8.03 per cent of the nouns in the C1 learner corpus are accounted for as C1 nouns in the EVP (e.g., negotiation, innovation, relevance, outcome, motivation) ––see Figure 9–– whereas the vast majority (79.84%) of nouns used are from lower levels (A1-B2), mainly B1 and B2, as shown in the following examples: game, students, people, country, village, hotel, letter (A1); price, news, photograph, company, machine (A2); employee, knowledge, opportunity, explanation, equipment, decision (B1); inhabitant, need, advantage, wish, emotion, therapy, anxiety, ambition (B2).
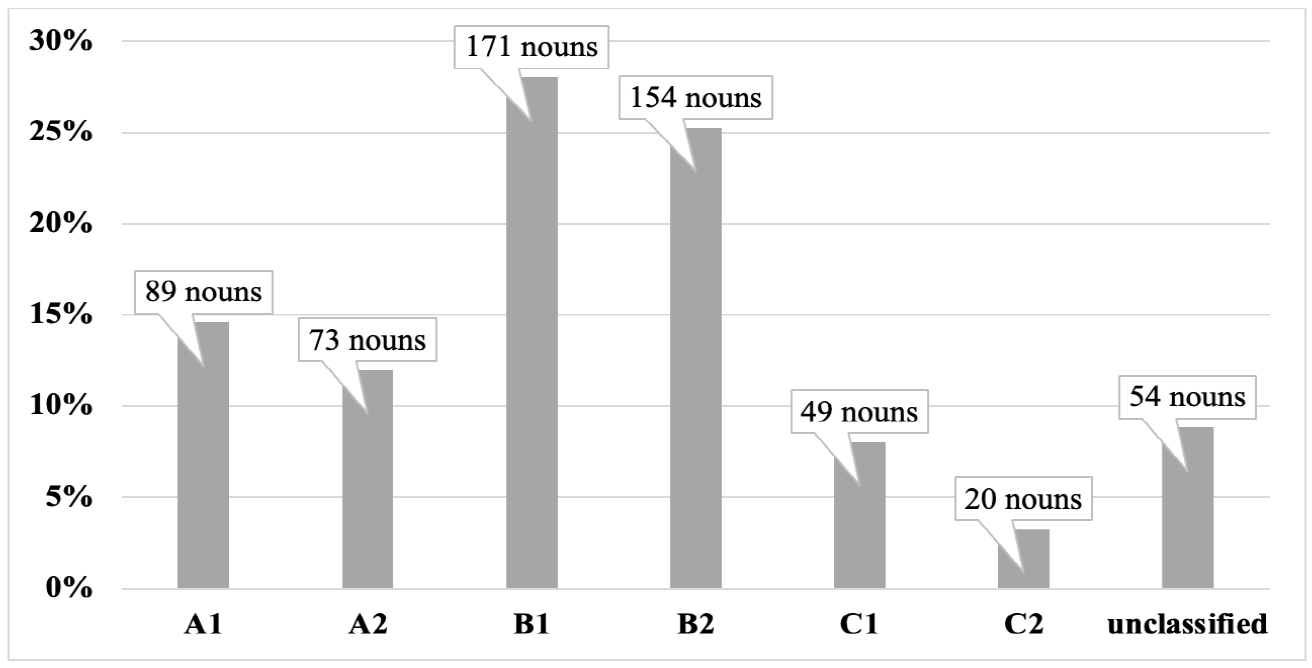
Figure 9: Comparison between the noun database in the C1 corpus and the EVP
The results confirm the initial expectation that there is a lower range of nouns in the B1 sample in comparison to the C1 learners’ sample, and they reflect that the study has considered the influence of topic and text type on the use of nouns from different semantic fields. As evidenced by Du et al. (2022: 8), the lexical choices made by language learners may be influenced by several variables, such as text types, genres, and registers (Biber and Conrad 1999; Hyland 2008) and so may EFL learners’ written production.
On the contrary, the comparison of the B1 and C1 learner subcorpora reveals unexpected results. In our sample, both at B1 and C1 levels, the percentage of nouns that, following the information in the EVP, belong to the target level is remarkably low. While the lexical choices of both B1 and C1 learners appear to be influenced by the specific tasks assigned to them, the observed distribution of nouns across CEFR levels raises interesting questions. This finding suggests that while learners may achieve a certain proficiency level, their lexical choices are not strictly confined to that level, indicating a more fluid progression in vocabulary acquisition. Further research could explore the factors influencing this variability, such as exposure to different text types, personal interests, and the pedagogical approaches employed in teaching vocabulary.
In conclusion, our study provides valuable insights into the lexical diversity of EFL learners at different proficiency levels, highlighting the need for a nuanced understanding of vocabulary development. By examining both quantitative data and qualitative nuances, educators and researchers can better support learners in expanding their lexical repertoire in a way that aligns with their communicative needs and proficiency goals.
4.2. NP complexity
Out of the 2,046 NPs in the learner corpus, 981 NPs were manually identified as premodified NPs, postmodified NPs or pre- and postmodified NPs (the remaining NPs were determiner NPs). The analysis of NP complexity in the 981 NPs was first conducted with NPs whose head nouns belong to a semantic field typical of CEFR B1 level in email writing by B1 and C1 learners, and was then carried out the NPs whose head nouns belong to a semantic field typical of CEFR B2. Inferential statistical analyses were then run to determine differences in the use of NP complexity types considering the two variables (semantic field typical of B1 or C1 and learner level, B1 or C1), see Tables 3 and 4.
The comparison of the NP complexity types, divided into premodified NPs, postmodified NPs, and pre- and postmodified NPs, in NPs whose head nouns belong to a semantic field typical of CEFR B1 level in the production by B1 and C1 learners reveals statistically significant differences in the production ––by B1 and C1 learners–– regarding only six hypernyms (out of the 34 considered), namely place, means of transport, clothing, time, utensil and communication (see Table 3 for hypernyms, NP complexity types and descriptive and inferential statistics).6 Therefore, words related to the other semantic fields typical of B1 (see Appendix 1) are used in the different NP complexity types with a similar frequency by students at B1 and C1 levels.
|
Hypernyms |
Np complexity type |
Statistics |
|||
|
|
|
p-value |
B1 Data |
C1 Data |
Mann-Whitney test and effect size |
|
Place |
Premodified NP |
p= .00 |
M= 9.23 SD= 7.93 Mdn= 7.49 IQR= 14.16 |
M = .83 SD= 1.94 Mdn= .00 IQR= .00 |
z= -5.950 U= 341.000 r= .63 |
|
|
Postmodified NP |
p= .00 |
M = 7.06 SD= 8.53 Mdn= 6.00 IQR= 12.28 |
M =.37 SD= 1.24 Mdn= .00 IQR= .00 |
z= -5.027 U= 501.000 r= .53 |
|
|
Pre- and postmodified NP |
p= .00 |
M = 3.88 SD= 4.15 Mdn= 4.88 IQR= 6.93 |
M =.15 SD= .72 Mdn= .00 IQR= .00 |
z= -5.194 U= 504.000 r= .55 |
|
Communication |
Premodified NP |
p=.00 |
M = 2.53 SD= 3.52 Mdn= .00 IQR= 5.78 |
M = 6.62 SD= 4.30 Mdn= 7.08 IQR= 5.93 |
z= -4.427 U= 478.500 r=.47 |
|
|
Postmodified NP |
p=.010 |
M = 2.69 SD= 5.24 Mdn= .0 IQR= 5.81 |
M = 4.64 SD= 5.15 Mdn= 3.53 IQR= 8.09 |
z= -2.579 U= 723.000 r= .27 |
|
|
Pre- and postmodified NP |
p=.022 |
M= .2850 SD= 1.32 Mdn= .00 IQR= .00 |
M= 1.10 SD= 2.24 Mdn= .00 IQR= .00 |
z= -2.295 U= 844.000 r= .24 |
|
Means of transport |
Premodified NP |
p=.00 |
M=3.26 SD= 4.38 Mdn= .00 IQR= 6.78 |
M=.18 SD= .84 Mdn= .00 IQR= .00 |
z= -4.304 U= 943.000 r= .45 |
|
Clothing |
Premodified NP |
p=.019 |
M=.78 SD= 2.21 Mdn= .00 IQR= .00 |
M= .00 SD= .00 Mdn= .00 IQR= .00 |
z= -2.338 U= 897.000 r= .25 |
|
Time |
Premodified NP |
p=.001 |
M=1.22 SD= 3.05 Mdn= .00 IQR= .00 |
M=3.03 SD= 2.87 Mdn= 3.72 IQR= 4.74 |
z= -3.414 U= 643.500 r= .36 |
|
Utensil |
Premodified NP |
p=.047 |
M=.00 SD= .00 Mdn= .00 IQR= .00 |
M=.37 SD= 1.22 Mdn= .00 IQR= .00 |
z= -1.989 U= 924.000 r= .21 |
Table 3: Hypernyms related to B1 which show statistically significant differences in the use of some NP complexity type by B1 and C1 learners
Second, the variety of NP complexity types which shows statistically significant differences in learner writing at B1 and C1 level per semantic field varies. As seen in Table 3, the head nouns corresponding to the hypernyms place and communication are found in premodified NPs, postmodified NPs and pre- and postmodified NPs which are more frequently employed either by C1 learners (in the case of communication head nouns) or B1 learners (with place head nouns), in the latter case with large effect sizes in all complexification types. The data point to B1 learners’ use of the three NP complexity types to describe places ––see (5) and (6)–– whereas the case is so for C1 learners with the head nouns related to communication, as illustrated in (7) and (8).
(5) taking one of the school (places_prem) courses (B1_1182)
(6) the (places_post) city where you and your family could enjoy… (B1_1247)
(7) give a (communication_post) talk about “How to improve your teaching” (C1_200002)
(8) the main (communication_prem_post) outlines of my speech (C1_200017)
However, the head nouns which belong to the other four hypernyms, namely utensil, time, means of transport and clothing, are found to differ in their frequency of use in premodified NPs only: learners at B1 level describe head nouns related to clothing and means of transport by means of premodification more than their C1 counterparts, whereas C1 learners do so with head nouns related to utensil and time, more abstract hypernyms The data in Table 3 also reveal that C1 students do not further describe clothing by means of premodification and B1 students do not do so with utensils.
Since the students at both levels were provided with the same writing task, no text-type effect or topic effect (cf. Biber and Gray 2011; Lu 2011; Polio and Park 2016; Staples et al. 2016; Staples and Reppen 2016; Bernardini and Gradfeldt 2019; Lan et al. 2019; Sarte and Gnevsheva 2022) may explain the differences in use of the NP complexity types when using head nouns in different semantic fields related to B1. It may be the case, however, that students at the lower level are more familiar with B1 words which have a more factual/concrete meaning, such as those describing places, clothing and means of transport, which favours their use and the complexification of the NPs in which they are head nouns, as illustrated in (9) and (10).
(9) wear winter (clothing_prem) clothes (B1_1280)
(10) … The public (means_of_transport_prem) transport is easy to use (B1_1279)
Our data reveal that the C1 learners, however, complexify more frequently the NPs whose head nouns express more abstract or specific words, i.e., those expressing time, communication, and utensils. They mainly do so by means of premodification ––as shown in (11) and (12)–– even though their higher language communicative competence would enable C1 students to employ any other complexification type (i.e., postmodification and/or pre- and postmodification), as they do with communication head nouns.
(11) because of modern (utensil_prem) instruments (C1_2000059)
(12) evening (time_prem) time (C1_200060)
This tendency suggests that complexification is lexically triggered, as the semantic properties of the head nouns have an effect on NP syntactic complexity. The use of different head nouns and complexification patterns at B1 and C1 levels characterise NP learner use at these two CEFR levels.
The data in Table 4 below show that nouns in nine semantic fields prototypical of CEFR C1 level were found in NP complexity types which show statistically significant differences in their use by B1 and C1 learners. In all cases, C1 learners employed the NP complexity types with those head nouns more frequently than B1 learners. These semantic fields are concept/content, abstraction, entity, ability, difficulty, state/attribute, possibility, social control, and commerce/exchange.
|
Hypernyms |
NP complexity type |
Statistics |
|||
|
|
|
p-value |
B1 Data |
C1 Data |
Mann-Whitney test and effect size |
|
Statue/attribute |
Premodified NP |
p= .00 |
M=.53 SD= 1.71 Mdn= .00 IQR= .00 |
M= 3.01 SD= 4.21 Mdn= .00 IQR=4.51 |
z= -3.732 U= 647.000 r= .39 |
|
|
Postmodified NP |
p=.00 |
M=.00 SD=.00 Mdn= .00 IQR= .00 |
M= 1.32 SD= 2.44 Mdn= .00 IQR=3.22 |
z= -3.607 U= 748.000 r= .38 |
|
|
Pre- and postmodified NP |
p=.007 |
M=.00 SD=.00 Mdn= .00 IQR= .00 |
M=.7151 SD= 1.76 Mdn= .00 IQR= .00 |
z= -2.677 U= 858.000 r= .28 |
|
Concept/content |
Premodified NP |
p=.00 |
M= .65 SD= 2.09 Mdn= .00 IQR= .00 |
M= 3.39 SD= 2.99 Mdn= 3.60 IQR=4.70 |
z= -4.975 U= 475.000 r= .52 |
|
|
Postmodified NP |
p=.00 |
M=.46 SD= 1.73 Mdn= .00 IQR= .00 |
M= 5.45 SD= 6.21 Mdn= 3.77 IQR= 8.68 |
z= -5.514 U= 422.000 r= .58 |
|
|
Pre- and postmodified NP |
p=.40 |
M=.88 SD= 2.68 Mdn= .00 IQR= .00 |
M= 1.40 SD= 2.20 Mdn= .00 IQR= 3.53 |
z= -2.058 U= 826.500 r= .22 |
|
Ability |
Premodified NP |
p=.002 |
M=.00 SD= .00 Mdn= .00 IQR= .00 |
M=.93 SD= 2.04 Mdn= .00 IQR= .00 |
z= -3.070 U= 814.000 r= .32 |
|
|
Pre- and postmodified NP |
p=.002 |
M=.00 SD= .00 Mdn= .00 IQR= .00 |
M=.76 SD= 1.58 Mdn= .00 IQR= .00 |
z= -3.070 U= 814.000 r= .32 |
|
Social control |
Premodified NP |
p=.047 |
M= .00 SD= .00 Mdn= .00 IQR= .00 |
M=.45 SD= 1.53 Mdn= .00 IQR= .00 |
z=-1.989 U= 924.000 r= .21 |
|
Commerce/exchange |
Premodified NP |
p=.047 |
M=.00 SD= 0 Mdn= 0 IQR= 0 |
M=.45 SD= 1.592 Mdn= .00 IQR= 0 |
z= -1.989 U= 924.000 r= .21 |
|
Possibility |
Postmodified NP |
p=.023 |
M=.42 SD= 2.00 Mdn= .00 IQR= .00 |
M= 1.05 SD= 2.08 Mdn= .00 IQR= .00 |
z= -2.268 U= 846.000 r= .24 |
|
Abstraction |
Postmodified NP |
p=.028 |
M= 1.69 SD= 3.473 Mdn= 0 IQR= 0 |
M= 2.83 SD= 3.460 Mdn= 3.20 IQR= 4 |
z= -2.196 U= 773.000 r= .23 |
|
Difficulty |
Postmodified NP |
p=.047 |
M=.00 SD=.00 Mdn= .00 IQR= .00 |
M=.37 SD= 1.22 Mdn= .0000 IQR= .00 |
z= -1.989 U= 924.000 r= .20 |
|
Entity |
Postmodified NP |
p=.005 |
M=.77 SD= 2.20 Mdn= .00 IQR= .00 |
M= 1.99 SD= 2.57 Mdn= .00 IQR= 4.42 |
z= -2.806 U= 741.5000 r= .30 |
Table 4: Hypernyms related to C1 which show statistically significant differences in the use of some NP complexity types by B1 and C1 learners
As was the case with the nouns in semantic fields related to B1, differences are found regarding the variety of NP complexity types in which head nouns classified into semantic fields related to C1 are statistically more frequently used by one learner group (C1 in all cases in which words related to C1 are considered). The hyponyms of the hypernyms concept/content and state/attribute are head nouns in the three possible NP complexity types (premodified NPs, postmodified NPs, and pre- and postmodified NPs), and the words related to ability are used as head nouns in premodified NPs and pre- and postmodified NPs. The words related to the other six semantic fields are employed as head nouns in only one NP complexity type whose use is higher in C1 production: social control and commerce/exchange are present in premodified NPs, whereas possibility, abstraction, difficulty and entity are in postmodified NPs. On some occasions, these differences are due to the B1 students’ decision not to employ NP complexity types with head nouns related to specific semantic fields typical of C1 level, contrarily to their complexification of head nouns related to the semantic fields in B1 (see Table 3). Table 4 shows that B1 learners do not postmodify or pre- and postmodify NPs in which the head refers to states/attributes, but rather premodify head nouns in that semantic field. In the case of the head nouns regarding ability, B1 students do not premodify or pre- and postmodify such heads. Premodified NPs are not found in the production by B1 students with noun-heads referring to social control and commerce/exchange and postmodified NPs are not employed by this learner group when expressing difficulty. These findings highlight that C1 students are ready to premodify, postmodify and pre- and postmodify head nouns in these semantic fields, whereas B1 students show some restrictions in their way to refer to states/attributes, ability, social control, commerce/exchange, and difficulty.
The data in Table 4 also reveal that differences in complexification of NPs whose head nouns are related to C1 level mainly involve postmodification,7 which C1 students produce more, either in postmodified NPs or in pre- and postmodified NPs. In line with the results by Sarte and Gnevsheva (2022) on the topic effect on NP complexity in which they concluded that more cognitively demanding topics favoured postmodification over premodification, the higher degree of abstractness of the nouns in semantic fields related to C1 may have triggered NP complexification to describe the referent better (cf. Lambert and Nakamura 2019) and have recurred to postmodification to do so.
In summary, the analysis of NP complexity and the head nouns reveals that B1 students complexify more concrete head nouns, whereas C1 learners complexify more abstract head nouns. When head nouns are concrete, both learner groups mainly use premodification. However, when the head nouns are abstract, B1 learners may not complexify those NPs, whereas C1 students do. With abstract head nouns, both learner groups mainly employ NP complexity types which involve postmodification, even though B1 learners do so much less frequently than their C1 counterparts.
The more frequent use of complexification types which involve postmodification with abstract head nouns is found to be in line with the findings by Sarte and Gnevsheva (2022) and Lambert and Nakamura (2019). It can be then claimed that there is a relation between the type of head nouns complexified and the complexification pattern employed. Furthermore, the data in our study also demonstrated that the students’ communicative language level also plays a fundamental role in both the selection of the words and the complexification patterns employed.
Further studies are needed to explore the role of these two CAF measures (lexical diversity and NP complexity) and communicative language level with learner corpora compiled with students’ from different L1s, proficiency levels, and this and other text types.
5. Conclusions
This study provides valuable information regarding the interaction of two complexity measures ––namely, noun lexical diversity and NP syntactic complexity–– in L1 Spanish EFL NP production at two CEFR levels. In doing so, this paper contributes to the still limited existing literature, which considers different lexical and syntactic measures to reach a more comprehensive understanding of NP learner production. Our data also offer insights from the analysis of an underexplored text type-email writing. This contribution fosters the analysis of non-academic text types that are crucial for meeting learners’ communicative needs and improving their performance in high-stakes language exams. While the study of the NP in email writing might present certain challenges for studying nominal diversity and syntactic complexity compared to more formal or extended text types, it also sheds light on language use in everyday written interactions. We believe that further research on registers which are considered non-academic is necessary so that we can reach a comprehensive understanding of NP use in learner English.
This investigation has answered the two research questions posed. Firstly, regarding RQ1, our analysis reveals that both B1 and C1 learners demonstrate limited use of nouns appropriate for their respective CEFR levels as per the EVP database. Secondly, concerning RQ2, our findings indicate that NP complexity is indeed influenced by the semantic fields of the head noun: B1 learners tend to exhibit more frequently NP complexification with concrete and factual nouns, while C1 learners show increased NP complexification, primarily through postmodification, with more abstract nouns. Our results show that the student’s selection of the head noun (concrete vs. abstract) interacts with the NP complexity type employed (pre- or postmodification). This interaction is found to be different at the two CEFR levels analysed.
Due to the different lexical and syntactic measures employed in the previous literature, the comparison of our results with those in the existing literature is limited. However, our results are in line with previous research which points to the relation between the semantic nature of the head noun and the NP complexity type employed (Lambert and Nakamura 2019; Sarte and Gnevsheva 2022). By analysing two CEFR levels, our study further explores how this lexical-syntactic relationship changes at B1 and C1 levels.
This paper offers results which may inform language teaching and learning as well as language assessment. First, language instruction and teaching materials may focus on the acquisition and production of vocabulary typical of each level and the different ways to complexify the NP. Language assessment can also benefit from the findings in this paper, as it provides a comprehensive understanding of the relevance of both noun lexical diversity and NP complexity in characterizing the writing proficiency level of L1 Spanish learners of English.
In summary, the implications of this study underline the importance of integrating activities and instructional approaches that promote and assess lexical diversity and NP syntactic complexity from a lexicogrammatical perspective to support the development of proficiency in EFL writing.
References
Agirre, Eneko, Oier López de Lacalle and Aitor Soroa. 2018. The risk of sub-optimal use of Open-source NLP Software: UKB is inadvertently state-of-the-art in knowledge-based WSD. NLP-OSS workshop at ACL (arXiv:1805.04277). https://doi.org/10.18653/v1/W18-2505
Ai, Haiyang and Xiaofei Lu. 2013. A corpus-based comparison of syntactic complexity in NNS and NS university students’ writing. In Ana Díaz-Negrillo, Nicolas Ballier and Paul Thompson eds. Automatic Treatment and Analysis of Learner Corpus Data. Amsterdam: John Benjamins, 249–264.
Allaw, Elissa. 2021. A learner corpus analysis: Effects of task complexity, task type, and L1 and L2 similarity on propositional and linguistic complexity. International Review of Applied Linguistics in Language Teaching 59/4: 569–604.
Ansarifar, Ahmad, Hesamoddin Shahriari and Reza Pishghadam. 2018. Phrasal complexity in academic writing: A comparison of abstracts written by graduate students and expert writers in applied linguistics. Journal of English for Academic Purposes 31: 58–71.
Bernardini, Petra and Jonas Granfeldt. 2019. On cross–linguistic variation and measures of linguistic complexity in learner texts: Italian, French and English. International Journal of Applied Linguistics 29/2: 211–232.
Biber, Douglas and Susan Conrad. 1999. Lexical bundles in conversation and academic prose. Language and Computers 26: 181–190.
Biber, Douglas and Bethany Gray. 2011. Grammatical change in the noun phrase: The influence of written language use. English Language and Linguistics 15/2: 223–250.
Biber, Douglas, Bethany Gray and Kornwipa Poonpon. 2011. Characteristics of conversation to measure complexity in L2 writing development. TESOL Quarterly 45/1: 5–35.
Biber, Douglas, Stig Johansson, Geoffrey N. Leech, Susan Conrad and Edward Finegan. 2021. Grammar of Spoken and Written English. Amsterdam: John Benjamins.
Bulté, Bram and Alex Housen. 2012. Defining and operationalising L2 complexity. In Alex Housen, Folkert Kuiken and Ineke Vedder eds. Dimensions of L2 Performance and Proficiency: Investigating Complexity, Accuracy and Fluency in SLA. Amsterdam: John Benjamins, 21-46.
Bulté, Bram and Alex Housen. 2014. Conceptualizing and measuring short-term changes in L2 writing complexity. Journal of Second Language Writing 26: 42–65.
Casal, J. Elliott and Joseph J. Lee. 2019. Syntactic complexity and writing quality in assessed first-year L2 writing. Journal of Second Language Writing 44: 51–62.
Clavel-Arroitia, Begoña and Barry Pennock-Speck. 2021. Analysing lexical density, diversity, and sophistication in written and spoken telecollaborative exchanges. Computer Assisted Language Learning Electronic Journal 22/3: 230–250.
Council of Europe. 2001. The Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Cambridge: Cambridge University Press.
Council of Europe. 2020. The Common European Framework of Reference for Languages: Learning, Teaching, Assessment. Companion Volume. Strasbourg: Council of Europe Publishing.
Crossley, Scott A., Kristopher Kyle and Danielle S. McNamara. 2016. The tool for the Automatic Analysis of Text Cohesion (TAACO): Automatic assessment of local, global, and text cohesion. Behavior research methods 48: 1227–1237.
Crossley, Scott A. and Danielle S. McNamara. 2014. Does writing development equal writing quality? A computational investigation of syntactic complexity in L2 learners. Journal of Second Language Writing 26: 66–79.
Crossley, Scott A., Tom Salsbury, Danielle S. McNamara and Scott Jarvis. 2011. Predicting lexical proficiency in language learner texts using computational indices. Language Testing 28/4: 561–580.
Díez-Bedmar, María Belén. 2015. Article use and criterial features in Spanish EFL writing. In Marcus Callies and Sandra Götz eds. Learner Corpora in Language Testing and Assessment. Amsterdam: John Benjamins, 163–190.
Díez-Bedmar, María Belén and Pascual Pérez-Paredes. 2020. Noun phrase complexity in young Spanish EFL learners’ writing: Complementing syntactic complexity indices with corpus analyses. International Journal of Corpus Linguistics 25/1: 1–33.
Du, Xiangtao, Muhammad Afzaal and Hind Al Fadda. 2022. Collocation Use in EFL Learners’ Writing Across Multiple Language Proficiencies: A Corpus-Driven Study. Frontiers in Psychology 13: 752134. https://doi.org/10.3389/fpsyg.2022.752134
Ellis, Rod and Fangyuan Yuan. 2004. The effects of planning on fluency, complexity, and accuracy in second language narrative writing. Studies in Second Language Acquisition 26: 59–84.
Engber, Cheryl A. 1995. The relationship of lexical proficiency to the quality of ESL compositions. Journal of Second Language Writing 4/2: 139–155.
Fellbaum, Christiane. 1998. WordNet: An Electronic Lexical Database. Cambridge: The MIT Press.
Foster, Pauline, and Peter Skehan. 1996. The influence of planning and task type on second language performance. Studies in Second Language Acquisition 18: 299–324.
Foster, Pauline, Alan Tonkyn and Gill Wigglesworth. 2000. Measuring spoken language: A unit for all reasons. Applied Linguistics 21/3 : 354–375.
Gaillat, Thomas, Andre Simpkin, Nicolas Ballier, Bernardo Stearns, Annanda Sousa, Manon Bouyé and Manel Zarrouk. 2022. Predicting CEFR levels in learners of English: The use of microsystem criteria features in a machine learning approach. ReCALL 34/2: 130–146.
Gregori-Signes, Carmen and Begoña Clavel-Arroitia. 2015. Analysing lexical density and lexical diversity in university students’ written discourse. Procedia-Social and Behavioral Sciences 198: 546–556.
Housen, Alex, Els Schoonjans, Sonja Janssens, Aurélie Welcomme, Ellen Schoonheere and Michel Pierrard. 2011. Conceptualizing and measuring the impact of contextual factors in instructed SLA –– the role of language prominence. International Review of Applied Linguistics in Language Teaching 49/2: 83–112.
Howarth, Peter. 1998. The phraseology of learners’ academic writing. In Anthony P. Cowie ed. Phraseology: Theory, Analysis, and Applications. Oxford: Oxford University Press, 161–186.
Hunt, Kellogg W. 1965. Grammatical Structures Written at Three Grade Levels. National Council of Teachers of English Research Report No. 3. Champaign: Office of Education CTE Champaign.
Hyland, Ken. 2008. As can be seen: Lexical bundles and disciplinary variation. English for Specific Purposes 27: 4–21.
Ionin, Tania and María Belén Díez-Bedmar. 2021. Article use in Russian and Spanish learner writing at CEFR B1 and B2 Levels: Effects of proficiency, native language, and specificity. In Bert Le Bruyn and Magali Paquot eds. Learner Corpus Research Meets Second Language Acquisition. Cambridge: Cambridge University Press, 10–38.
Khushik, Ghulam Abbas and Ari Huhta. 2020. Investigating syntactic complexity in EFL learners’ writing across Common European Framework of Reference levels A1, A2 and B1. Applied Linguistics 41/4: 506–532.
Kim, Jungyeon. 2021. Measuring NP complexity in Korean EFL writing across CEFR levels A2, B1 and B2. Korean Journal of English Language and Linguistics 21: 341–358.
Kisselev, Olesya, Rossina Soyan, Dmitrii Pastushenkov and Jason Merrill. 2022. Measuring writing development and proficiency gains using indices of lexical and syntactic complexity: Evidence from longitudinal Russian learner corpus data. The Modern Language Journal 106/4: 798–817.
Kuiken, Folkert and Ineke Vedder. 2019. Syntactic complexity across proficiency and languages: L2 and L1 writing in Dutch, Italian and Spanish. International Journal of Applied Linguistics 29/2: 192–210.
Kuiken, Folkert, Ineke Vedder and Roger Gilabert. 2010. Communicative adequacy and linguistic complexity in L2 writing. In Inge Bartning, Maisa Martin and Ineke Uedder eds. Communicative, Proficiency and Linguistic Development: Intersections between SLA and Language Testing Research. Stockholm: European Second Language Association, 81–100.
Kyle, Kristopher. 2016. Measuring Syntactic Development in L2 Writing: Fine Grained Indices of Syntactic Complexity and Usage-based Indices of Syntactic Sophistication. Atlanta, GA: Georgia State University dissertation.
Kyle, Kristopher and Scott A. Crossley. 2015. Automatically assessing lexical sophistication: Indices, tools, findings, and application. TESOL Quarterly 49/4: 757–786.
Kyle, Kristopher and Scott A. Crossley. 2018. Measuring syntactic complexity in L2 writing using fine-grained clausal and phrasal indices. The Modern Language Journal 102/2: 339–349.
Lahmann, Cornelia, Rasmus Steinkrauss and Monika S. Schmid. 2019. Measuring linguistic complexity in long-term L2 speakers of English and L1 attriters of German. International Journal of Applied Linguistics 29: 173–191.
Lahuerta Martínez, Ana Cristina. 2018. Analysis of syntactic complexity in secondary education EFL writers at different proficiency levels. Assessing Writing 35: 1–11.
Lahuerta Martínez, Ana Cristina. 2023. Analysis of changes in L2 writing over the time of a short-term academic English programme. Porta Linguarum 39: 111–127.
Lahuerta Martínez, Ana Cristina. 2024. The role of syntactic and lexical complexity in undergraduate writing quality. Ibérica 47: 251–274.
Lambert, Craig and Sachiko Nakamura. 2019. Proficiency‐related variation in syntactic complexity: A study of English L1 and L2 oral descriptive discourse. International Journal of Applied Linguistics 29/2: 248–264.
Lan, Ge, Kyle Lucas and Yachao Sun. 2019. Does L2 writing proficiency influence noun phrase complexity? A case analysis of argumentative essay written by Chinese students in a first-year composition course. System 85: 1–13.
Lan, Ge, Qiusi Zhang, Kyle Lucas, Yachao Sun and Jie Gao. 2022. A corpus-based investigation on noun phrase complexity in L1 and L2 English writing. English for Specific Purposes 67: 4–17.
Liu, Liming and Lan Li. 2016. Noun phrase complexity in EFL academic writing: A corpus-based study of postgraduate academic writing. The Journal of Asia TEFL 13/1: 48–65.
Lu, Xiaofei. 2010. Automatic analysis of syntactic complexity in second language writing. International Journal of Corpus Linguistics 15: 474–496.
Lu, Xiaofei. 2011. A corpus-based evaluation of syntactic complexity measures as indices of college-level ESL writers’ language development. TESOL Quarterly 45/1: 36–62.
Lu, Xiaofei. 2012. The relationship of lexical richness to the quality of ESL learners’ oral narratives. The Modern Language Journal 96/2: 190–208.
Lu, Xiaofei and Jifeng Wu. 2022. Noun-phrase complexity measures in Chinese and their relationship to L2 Chinese writing quality: A comparison with topic-comment-unit-based measures. The Modern Language Journal 106/1: 267–283.
Martínez Mimbrera, Francisco Javier. 2021. Tags Retrieval [Computer software]. Jaén: Universidad de Jaén.
Mazgutova, Diana and Judit Kormos. 2015. Syntactic and lexical development in an intensive English for Academic Purposes programme. Journal of Second Language Writing 29: 3–15.
Nation, Ian S. P. 2001. Learning Vocabulary in nother Language. Cambridge: Cambridge University Press.
Norris, John M. and Lourdes Ortega. 2009. Towards an organic approach to investigating CAF in instructed SLA: The case of complexity. Applied Linguistics 30: 555–578.
North, Brian. 2021. The CEFR Companion Volume––What’s new and what might it imply for teaching/learning and for assessment? CEFR Journal: Research and Practice 4: 5–24.
Ong, Justina and Lawrence Jun Zhang. 2010. Effects of task complexity on the fluency and lexical complexity in EFL students’ argumentative writing. Journal of Second Language Writing 19/4: 218–233.
Ortega, Lourdes. 2003. Syntactic complexity measures and their relationship to L2 proficiency: A research synthesis of college-level L2 writing. Applied Linguistics 4/4: 492–518.
Padró, Lluís, Samuel Reese, Eneko Agirre and Aitor Soroa. 2010. Semantic services in FreeLing 2.1: WordNet and UKB. In Pushpak Bhattacharyya, Christiane D. Fellbaum and Piek Vossen eds. Principles, Construction, and Application of Multilingual Wordnets. Mumbai: Narosa Publishing House, 99–105.
Padró, Lluís and Evgeny Stanilovsky. 2012. FreeLing 3.0: Towards wider multilinguality. In Nicoletta Calzolari, Khalid Choukri, Thierry Declerk, Mehmet Ugur Dogan, Bente Maegaard, Joseph Mariani, Asunción Moreno, Jan Odijk and Stelios Peiperidis eds. Proceedings of the 8th the Language Resources and Evaluation Conference. Istanbul: European Language Research Asociation, 2473–2479.
Paquot, Magali. 2019. The phraseological dimension in interlanguage complexity research. Second Language Research 35/1: 121–145.
Parkinson, Jean and Jill Musgrave. 2014. Development of noun phrase complexity in the writing of English for Academic Purposes students. Journal of English for Academic Purposes 14: 48–59.
Peters, Elke. 2016. The learning burden of collocations: The role of interlexical and intralexical factors. Language Teaching Research 20: 113–138.
Polat, Brittany and Youjin Kim. 2014. Dynamics of complexity and accuracy: A longitudinal case study of advanced untutored development. Applied Linguistics 35/2: 184–207.
Polio, Charlene and Ji-Hyun Park. 2016. Language development in second language writing. In Rosa María Manchón and Paul Kei Matsuda eds. Handbook of Second Language Writing. New York: Routledge, 287–306.
Qin, Wenjuan and Paola Uccelli. 2020. Beyond linguistic complexity: Assessing register flexibility in EFL writing across contexts. Assessing Writing 45: 100465. https://doi.org/10.1016/j.asw.2020.100465
Ravid, Dorit and Ruth A. Berman. 2010. Developing noun phrase complexity at school age: A text-embedded cross-linguistic analysis. First Language 30/1: 3-26.
Sarte, Kayla Marie and Ksenia Gnevsheva. 2022. Noun phrasal complexity in ESL written essays under a constructed-response task: Examining proficiency and topic effects. Assessing Writing 51: 100595. https://doi.org/10.1016/j.asw.2021.100595
Šišková, Zdislava. 2012. Lexical richness in EFL students’ narratives. Language Studies Working Papers 4: 26–36.
Skehan, Peter. 1989. Individual differences in Second Language Learning. London: Hoder Arnold.
Staples, Shelly and Randi Reppen. 2016. Understanding first-year L2 writing: A lexico-grammatical analysis across L1s, genres, and language ratings. Journal of Second Language Writing 32: 17–35.
Staples, Shelley, Jesse Egbert, Douglas Biber and Bethany Gray. 2016. Academic writing development at university level: Phrasal and clausal complexity across level of study, discipline and genre. Written Communication 33/2: 149–183.
Su, Yanfang, Kanglong Liu, Fengkai Liu, John Lee and Tan Jin. 2023. Lexical complexity in exemplar EFL texts: Towards text adaptation for 12 grades of basic English curriculum in China. International Review of Applied Linguistics in Language Teaching 62/1: 137–164.
Treffers-Daller, Jeanine, Patrick Parslow and Shirley Williams. 2018. Back to basics: How measures of lexical diversity can help discriminate between CEFR levels. Applied Linguistics 39/3: 302–327.
Vedder, Ineke and Veronica Benigno. 2016. Lexical richness and collocational competence in second-language writing. International Review of Applied Linguistics in Language Teaching 54/1: 23–42.
Vidal, Karina and Scott Jarvis. 2020. Effects of English-medium instruction on Spanish students’ proficiency and lexical diversity in English. Language Teaching Research 24/5: 568–587.
Vyatkina, Nina. 2013. Specific syntactic complexity: Developmental profiling of individuals based on an annotated learner corpus. The Modern Language Journal 97/S1: 11–30.
Wolfe-Quintero, Kathryn Elizabeth, Shunji Inagaki and Hae-Young Kim. 1998. Second Language Development in Writing: Measures of Fluency, Accuracy and Complexity. Honolulu: University of Hawai’i at Manoa.
Xu, Lirong. 2019. Noun phrase complexity in integrated writing produced by advanced Chinese EFL learners. Papers in Language Testing and Assessment 8/1: 31–51.
Yoon, Hyung-Jo. 2017. Linguistic complexity in L2 writing revisited: Issues of topic, proficiency, and construct multidimensionality. System 66: 130–141.
Zhang, Xiaopeng and Xiaofei Lu. 2022. Revisiting the predictive power of traditional vs. fine-grained syntactic complexity indices for L2 writing quality: The case of two genres. Assessing Writing 51: 100597. https://doi.org/10.1016/j.asw.2021.100597
Appendices
Appendix 1: B1 Hypernym database
|
|
List of Hypernyms |
Number of hyponyms |
|
List of Hypernyms |
Number of hyponyms |
|
|
1 |
Place |
74 |
24 |
State/attribute |
3 |
|
|
2 |
Activity |
30 |
25 |
Title |
3 |
|
|
3 |
Communication |
25 |
26 |
Category |
2 |
|
|
4 |
Time period |
21 |
27 |
Condition |
2 |
|
|
5 |
Person |
16 |
28 |
Language unit |
2 |
|
|
6 |
Event |
11 |
29 |
Meal |
2 |
|
|
7 |
Means of transport |
9 |
30 |
Navigational system |
2 |
|
|
8 |
Abstraction |
8 |
31 |
System of measurement |
2 |
|
|
9 |
Entity |
8 |
32 |
Ability |
1 |
|
|
10 |
Clothing |
7 |
33 |
Charge |
1 |
|
|
11 |
Concept/content |
7 |
34 |
Container |
1 |
|
|
12 |
Feeling |
7 |
35 |
Creation |
1 |
|
|
13 |
Food/drink |
7 |
36 |
Decision-making process |
1 |
|
|
14 |
Group |
6 |
37 |
Game equipment |
1 |
|
|
15 |
Proper names |
6 |
38 |
Housing |
1 |
|
|
16 |
Body part |
5 |
39 |
Imagination |
1 |
|
|
17 |
Animal |
4 |
40 |
Incentive |
1 |
|
|
18 |
Creation |
4 |
41 |
Knowledge |
1 |
|
|
19 |
Value |
4 |
42 |
Precious stone |
1 |
|
|
20 |
Difficulty |
3 |
43 |
Representation |
1 |
|
|
21 |
Environment |
3 |
44 |
Software |
1 |
|
|
22 |
Game |
3 |
45 |
Software |
1 |
|
|
23 |
Possibility |
3 |
46 |
Trademark |
1 |
|
|
Total number of noun lexemes 304 |
|
|||||
Appendix 2: C1 Hypernym database
|
|
List of Hypernyms |
Number of hyponyms |
|
List of Hypernyms |
Number of hyponyms |
|
1 |
Communication |
66 |
34 |
Process |
4 |
|
2 |
Activity |
52 |
35 |
(Financial) Gain |
3 |
|
3 |
Person |
49 |
36 |
Accomplishment |
3 |
|
4 |
Time period |
44 |
37 |
Beginning |
3 |
|
5 |
Proper name |
42 |
38 |
Medical care |
3 |
|
6 |
Concept/content |
38 |
39 |
Social control |
3 |
|
7 |
Abstraction |
32 |
40 |
Software |
3 |
|
8 |
State/attribute |
32 |
41 |
Substance |
3 |
|
9 |
Event |
30 |
42 |
Web |
3 |
|
10 |
Group |
25 |
43 |
Certainty |
2 |
|
11 |
Place |
25 |
44 |
Facility |
2 |
|
12 |
Feeling |
19 |
45 |
Force/strength |
2 |
|
13 |
Entity |
17 |
46 |
Game |
2 |
|
14 |
Ability |
12 |
47 |
Growth |
2 |
|
15 |
Utensil |
12 |
48 |
Clothing |
1 |
|
16 |
Creation |
11 |
49 |
Combustion |
1 |
|
17 |
Body part |
10 |
50 |
Commercial document |
1 |
|
18 |
Commerce/exchange |
9 |
51 |
Conformity |
1 |
|
19 |
Part/portion |
9 |
52 |
Cost |
1 |
|
20 |
Explanation |
7 |
53 |
Courage |
1 |
|
21 |
Food/drink |
7 |
54 |
Crystal |
1 |
|
22 |
Measurement |
7 |
55 |
Curiosity |
1 |
|
23 |
Condition |
6 |
56 |
Decision-making |
1 |
|
24 |
Database |
5 |
57 |
Duty |
1 |
|
25 |
Difficulty |
5 |
58 |
Epidemic disease |
1 |
|
26 |
Equipment |
5 |
59 |
Housing |
1 |
|
27 |
Health issues |
5 |
60 |
Imagination |
1 |
|
28 |
Object |
5 |
61 |
Influence |
1 |
|
29 |
Possibility |
5 |
62 |
Killing |
1 |
|
30 |
Value |
5 |
63 |
Metal |
1 |
|
31 |
Category |
4 |
64 |
Perception |
1 |
|
32 |
Language unit |
4 |
65 |
Title |
1 |
|
33 |
Means of transport |
4 |
|
|
|
|
Total number of noun lexemes 664 |
|||||
Notes
1 This paper was supported by Grant PID2020-117041GA-I00, funded by MICIU/AEI/10.13039/501100011033. The authors would like to thank Arturo Montejo Ráez for his valuable assistance in the automatic annotation of nouns in our study. [Back]
2 Different labels are used in the literature to refer to the phrase whose head is a noun or a pronoun. The umbrella term is ‘noun phrase’, which does not further specify if the head is modified in any way. Complex nominals, however, designate a premodified and/or postmodified NP. When complex nominals are analysed, specifications of the premodification and/or postmodification patterns under study are provided. [Back]
3 The T-unit is defined as “one main clause plus the subordinate clauses attached to or embedded within it” (Hunt 1965: 49). [Back]
4 An AS-unit stands for Analysis of Speech unit and refers to a unit of speech or writing that consists of a main clause and any subordinate clauses associated with it (Foster et al. 2000). [Back]
5 Further information on the FineDesc Research Project can be found at https://web.ujaen.es/investiga/finedesc/index.php [Back]
6 The descriptive statistics reported in Tables 3 and 4 are the means (M), standard deviations (SD), medians (Mdn) and interquartile ranges (IQR), the latter provided because of the non-normal distribution of the data which required the use of non-parametric tests. Then, the results of the Mann-Whitney tests are offered by reporting the Mann-Whitney U value, the z value as well as the effect size for each comparison. [Back]
7 In fact, only the hypernyms social control and commerce/exchange are not present in statistically significant NP complexity types which involve postmodification. [Back]
Corresponding author
Natalia Judith Laso Martín
University of Barcelona
Department of Modern Languages and Literatures and English Studies
Gran Via de les Corts Catalanes, 585
08007 Barcelona
Spain
E-mail: njlaso@ub.edu
received: May 2024
accepted: October 2024